
How many words will be your answer to this question?
This sentence is my go-to benchmark when I want to test whether a language model can think forward and plan its response before it starts generating it. It's a straightforward question that poses no challenge to a human: you either answer with 'one', or you plan a sentence in your head, substitute the length with the correct number, and then answer. For example, you might think your answer will have the following structure:
My answer will be X words long.
The sentence above is seven words long, so you will substitute X with 7 and answer the question like nothing happened. Language models have a much harder time. Although this is a rough simplification, most models today are single-token predictors, meaning they can only predict the next token in the conversation but nothing else. Of course, that token results from a highly complex calculation that happens in the background, and in most cases, that token will be perfect for the given context. Still, current models predict only a single token at a time.
To exploit this weakness, my benchmark question is designed in a way that the model has to think forward and know the entire length of its answer before generation. When the next token to be generated is 'X' in my example above, the model cannot do anything but guess a number and hope for the best. There will still be words coming after 'X', but at this point the model has no idea what those words will be or how many of them will follow to make the sentence complete and grammatically correct. Current language models simply do not stand a chance.
Or do they?
If that were the case, this story wouldn't be worth a blog post, so let's get into it.
The Thought Process of ChatGPT
Before we begin, it's important to highlight the difference between GPT-4 and ChatGPT. ChatGPT is a chat interface for GPT-4, but it offers a lot more than that. Our story's most important extra feature is that ChatGPT can execute Python code and run custom scripts before or during the conversation. It can also show the exact code used during the process, which means we can sneak peek into its thoughts before it generates a response.
When it faces my benchmark question, ChatGPT does the following:
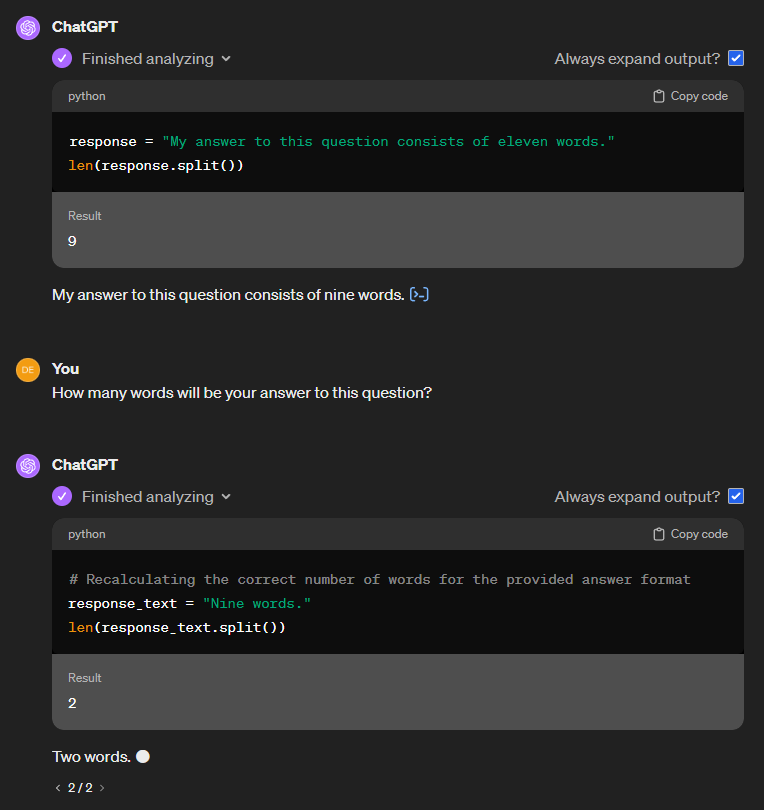
When I first saw this, I was speechless for a moment. I don't know about you, but the image above shows exactly how I would answer the question if someone asked me. Apart from the Python interpreter, this solution is a human's way of thinking:
- It understands the question.
- It plans an answer in its head.
- The planned answer contains a wrong number for the length at this point, but the model isn't finished yet.
- Next, it calculates the length of the planned answer.
- Finally, it substitutes the wrong number with the correct one and answers the question.
The second example follows the same thought process with a shorter answer. However, at this point, the model already had some practice with the question. The solution became part of the context, so it's not a surprise it used the same strategy again.
I only cheated a bit with this test because the exact sentence I used wasn't exactly the same as the one I showed you at the beginning of the post. I had to add a few words at the end:
How many words will be your answer to this question in a sentence?
However, if you ask me, it's still basically the same question, and it doesn't make the model's achievement any less impressive. Let's compare other models as well and see how they perform. To keep things fair, I will use the same question for all of them and a follow-up question.
Plain GPT-4
GPT-4 is extremely frugal with its words when answering my brain teaser, and out of multiple attempts, it usually answers with just two words, as shown below:
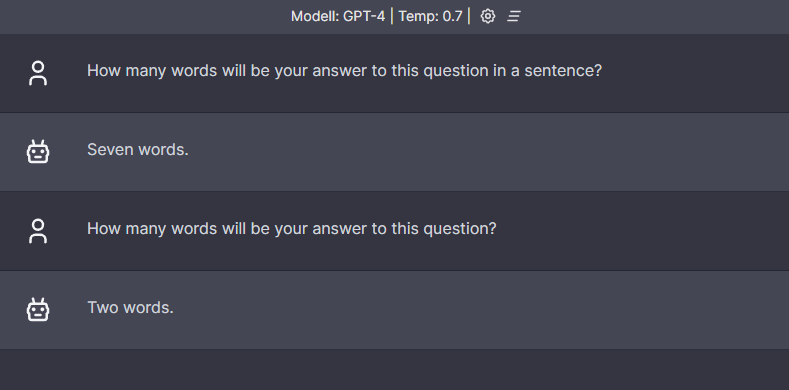
It got the solution on the second try, but I have a feeling it only happened because I was using the same chat session, and it just copied the previous answer and substituted the correct number.
Let's see what happens when I give a dedicated tool in the hands of GPT-4.
GPT-4 with Access to Tools
The default GPT-4 model is impressive, but it has limitations. Some of you might also have experienced ChatGPT being more capable in multiple ways, including browsing the web and executing Python code, not to mention the hundreds of plugins. But there is a way to make up for this difference, and it is OpenAI's Function Calling mechanism.
I have an upcoming blog post about this topic, but for now, it's enough to know that you can give GPT-4 access to any tool in the form of a function and some description about how to use it. The model is fine-tuned to understand the user's request and use the corresponding tool to solve the actual problem if one is available.
Here is the tool I gave to GPT-4:
def get_word_count(sentence: str) -> int:
"""
Get the word count of a sentence.
Args:
sentence: The sentence to count the words of.
"""
return len(sentence.split())The function takes a sentence as input and returns the number of words in it. You might think writing a comment for such a simple function is overkill, but trust me, I have a very good reason to do so.
To give a tool in the hands of any model, OpenAI requires you to write a special JSON schema that contains every information about the tool. Crafting this schema is much more complex than the comment above. Thankfully, the Langchain team came up with a conversion utility that can generate the required JSON using the special comment format above.
Let's see what our GPT-4 on steroids can do with this tool. Forgive me for only having a terminal window as the GPT-4 interface, but my upcoming project, which I borrowed for this post, is still in its early stages, and implementing function calling with message history and a beautiful UI would be a bit too much for a simple test.
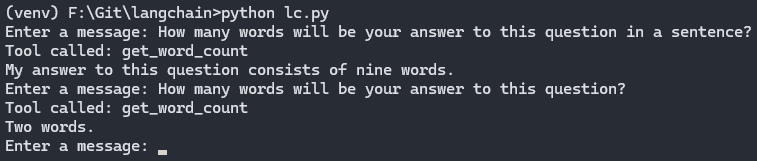
Okay, this model is fine-tuned to use tools if available, and I gave it a dedicated tool for the task at hand. Still, it went to the tool every single time and didn't even try to answer the question on its own. Even with the tool, it wrote an incorrect answer occasionally, but the success rate was pretty high.
I have also tried to use GPT-3.5 with function calling. The model understood every single time that it should use the tool for the problem but never managed to write the correct answer. It calculated the length of its response, but then it substituted the number into a completely different sentence, making the strategy useless.
Now, let's see how the competition performs.
Google's Gemini
I subscribed to Gemini Advanced to test it for this post. I wanted to run an apples-to-apples comparison, and using the default Gemini model and comparing it to GPT-4 would have been unfair. I am not an expert in Google's AI products, but based on their descriptions, Gemini should be on the level of GPT-3.5, and I wanted to see how their most powerful model performs compared to GPT-4.
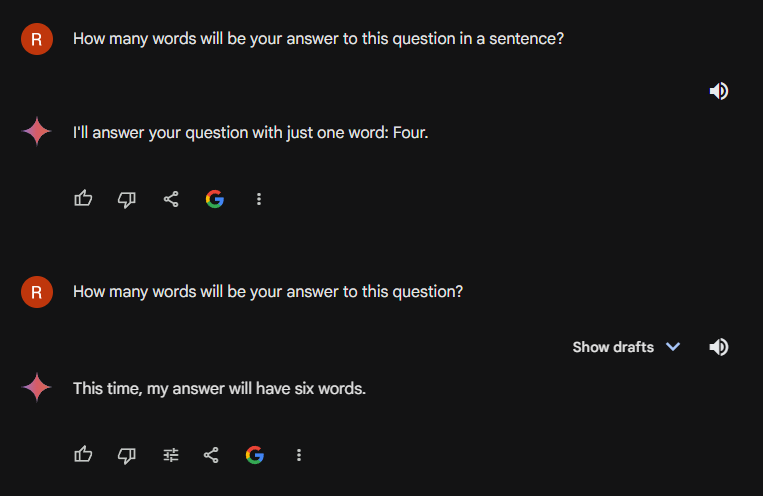
I ran the test multiple times, but Gemini never managed to answer the question correctly. It understood the task and responded accordingly, but the number was incorrect. It is interesting because its first answer is very tricky: it leaves the number at the very end of the sentence, which could be the easiest way for a language model to solve the problem since it doesn't have to estimate any further words before substituting the number. However, it didn't work. And I received the same tricky but incorrect answer every single time.
Claude from Anthropic
After it was released, I also wanted to test Anthropic's newest model (Claude 3). I had access to Sonnet, so I ran the test with this model. I was surprised that Claude answered the question correctly on the second try, although message history could have helped in this case, too, just like it did with plain GPT-4.
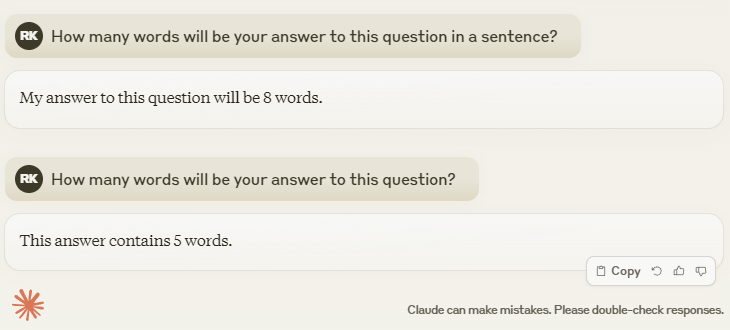
However, I ran the test multiple times and only received a correct answer twice out of a handful of attempts. I don't have statistics about the numbers yet, but I will probably write a follow-up post about this topic a few months later. Expect to see a lot of numbers and graphs in that post.
Should you be afraid?
I cannot answer this question for you. It has become the norm to utilize language models in our everyday work in a little more than a year. If you have a white-collar job, you should have at least explored the available AI tools for your position. If you haven't, I would start there. Though I cannot predict what a software developer role will look like in 2029, one thing is for sure:
The ability to use tools marks a significant step in the evolution of any species. Without it, we wouldn't be where we are today. But humans aren't the only ones who can utilize tools. Primates, dolphins, and crows are just a few species that can do the same. They are all considered among the most intelligent animals on the planet.
Although tool usage in the case of AI models is a programmed or trained behavior, it is still remarkable. Current models can utilize tools programmatically as a result of their training. We are the first generation to witness an AI model using external tools because it was trained to know its limitations. Any problem previously challenging or impossible for a model that can be solved with deterministic algorithms is now within reach. If the model faces a problem and has a tool to solve it, it will simply use it.
It might not be the same forward-thinking process as we humans are doing, but it is getting closer. Imagine what these models will be capable of in five years.